Background | Enter Data | Analyze Data | Interpret Data | Report Data
Let’s start with an example
I’m going to use this example to help you understand how to enter the data. Suppose you want to study the effect of sugar (IV) on memory for words (DV). You have two groups (also called conditions) in your experiment, sugar and no sugar. Each participant only participates in one condition of the experiment. Participants in the first condition are not related in any way to participants in the second condition. Because the participants in each condition are not related in any way, we will use the Independent Samples T-Test. Here are the data.
|
Condition 1: Sugar |
Condition 2: No Sugar |
|
Participant 1 = 3 words Participant 2 = 6 words Participant 3 = 4 words Participant 4 = 3 words Participant 5 = 5 words |
Participant 1 = 2 words Participant 2 = 2 words Participant 3 = 1 words Participant 4 = 3 words Participant 5 = 3 words |
What you want to know
In this experiment, you want to know if there is a significant different between the data collected from each condition, sugar and no sugar. You want to know if sugar really does have an effect on memory for words. Does word memory significantly increase or decrease when people eat sugar? Is there no difference in word memory for sugar and no sugar conditions?
Why not just look at the data?
Just looking at the data, you can probably see that there is a difference in word memory between the two conditions. You can probably see that word memory in the sugar condition appears to be much better than word memory in the no sugar condition. People generally appear to remember more words when they have eaten sugar. So you might be wondering, why can’t I just look at the data? Why do I have to conduct this t-test? The reason is that we are not just trying to figure out if there is a difference in words recalled between each group. We want to know if there is a statistically significant difference. That is, a real difference as defined by statistics. The t-test will be able to tell us that.
You will use the first two columns of your SPSS data file to enter the data for the independent samples t-test.
The first column
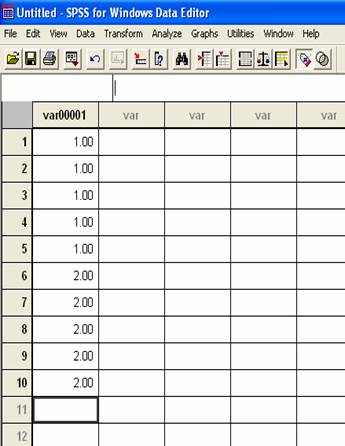
In this column, you should type in two different numbers to represent each of your two conditions. For example, you could use the numbers 1 and 2 to represent your two conditions. The 1s could be used to represent the sugar condition and the 2s could be used to represent the no sugar condition. Take a look at what I’m talking about below. You can see one column of data with 1s and 2s. There are five 1s. They will represent data from the five participants in the first condition, sugar. Below the 1s are five 2s. They will represent data from the five participants in the second condition, no sugar. The number of 1s and 2s that you use will vary, depending on how many participants you have in each condition.
What can’t we just type in the names sugar and no sugar?
That would make things a lot easier, wouldn’t it? This version of SPSS will not let you directly type in labels like sugar and no sugar into the data file. You can convert the 1s and 2s into these labels but I will spare you of that for now.
Name the first column
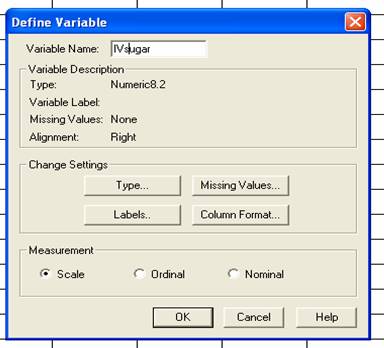
Double click on the top of the first column to name it. The Define Variable box will pop up and you can enter a new name for the variable in the Variable Name area. Give the variable a meaningful name. This will make your life a lot easier when you analyze the data and interpret the results. Because this column represents the two conditions of the IV, it is a good idea to use the letters “IV” in the name of the variable. You might also want to include a word that describes what is being manipulated. In the below example, I decided to name my variable “IVsugar.” I decided on this name because this variable is an IV in which the presence of sugar is being manipulated. Click OK when you are finished using the Define Variable box and it will disappear.
The second column
In this column, you should type in the actual data collected for each participant in each condition. In the example, each data point represented the number of words remembered.
Enter your data one condition at a time
Start by entering the data from the first condition of your experiment into the second column of the data file. In this example the first condition was sugar. Each data point from the sugar condition should be typed next to a 1 from the first column. This configuration tells SPSS that all the data points next to a 1 are from condition 1, sugar.

Now for the next condition
When you are finished entering the data from the first condition, it is time to move on to the second condition. Enter the data from the second condition below the data from the first condition. Each data point from the second condition should be typed next to a 2 from the first column. This configuration tells SPSS that all the data points next to a 2 are from condition 2, no sugar.

Name the second column
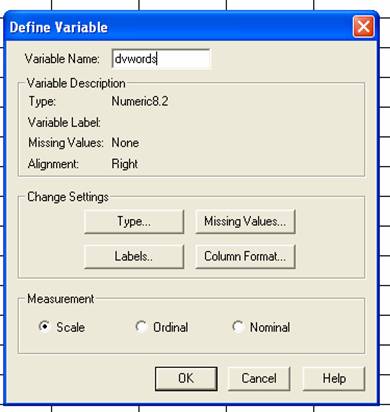
Double click on the top of the second column to name it. Enter a name into the variable name box. The second column represents your DV. Because of this, it’s a good idea to include the letters “DV” in the name of the second column. It is also a good idea to include the name of what is being measured. Since words are being measured in this example, I decided to name my variable “dvwords.” Click OK when you are finished.
Almost finished
But don’t forget to save the data file to a meaningful place with a meaningful name. I decided to name my data file “Effect of Sugar on Words Remembered Data.sav.” It’s a long name but this file will be very easy for me to identify in the future. See how I used the word “Data” in the name? This will help me to know that this is my data file in the future, as compared to my output file which might have a similar name.
Background | Enter Data | Analyze Data | Interpret Data | Report Data